150x Speedup in Real-Time Dashboards with Postgres 9.5
Originally posted on Medium

As I was taking in the beauty of Big Sur during Thanksgiving weekend, an alert goes off indicating that the Botmetrics (the conversational intelligence platform we’re building) was experiencing high page-load latencies for our dashboards pages.
We’d just signed up a large customer the previous week and while we were processing millions of events per day (3–5k requests per minute), our query engine was having intermittent trouble (with request latencies >15s) digesting large volumes of data.
With the help of our friends at Citus, we re-architected our system in a matter of days, and were able to speed up our query engine 150x. This is how we did it.

Journey from a 100’s of req/min to 1000’s of req/min
Botmetrics is a conversational intelligence platform that allows customers to measure and analyze conversations. We support Facebook, Kik, Slack, SMS (Twilio), Google Home and web-based conversations. We did have a couple of high volume customers but a week before Thanksgiving, we onboarded one of the top Facebook Messenger bots on our platform and the volume of data we were processing increased by an order of magnitude.
Stepping Back: Our Data Model
Botmetrics uses Postgres as its primary data store and has served us well. The key data model that is relevant to this story is the **_events_** table — which stores all of the different events that are sent by our customers (these can include events such as plain text, but also complicated structured data such as images, location coordinates, button clicks and so on). Different messenger platforms have different data schemas for their message payloads but with Postgres’ JSONB data structure, we are able to ingest all of the varied data and store them in a single table.
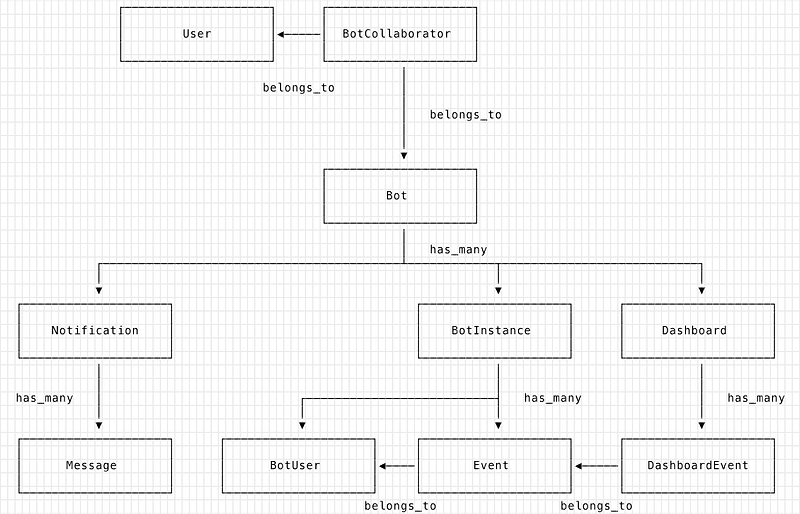
With JSONB, we can set uniqueness constraints on child elements of the JSON column so that we don’t duplicate events. For e.g. Facebook uses a combination of mid and seq to determine the uniqueness of an event, Slack uses a combination of channel_id and timestamp and with Postgres we are able to set conditional uniqueness constraints (depending on the messenger platform).
The Original Data Flow Design
As with any well-designed event ingestion architecture, our Events Collection API is decoupled from the Events Processing Engine, thus allowing us to scale each component independently. The HTTP endpoints queues up events in our message queue and event processors then pick up the events and performs pre-processing on it (validation, normalization of data fields and de-deduplication) before INSERTing into the events table in Postgres.

The Query Engine would then query the events table to generate time-series data, which is used by the web frontend to display the pretty graphs and tables.
Limits of The Design
The limitation of this design is that as the number of rows in the database approaches tens of millions, querying this table (even with good indexes) results in very large query times. Some queries require >15s query time which results in an inferior user experience.

Use the Rollups, Luke
One of the solutions (which we had intended to get to at some point) is for the engine to not query the events table directly but to cache the counts in a separate column or table and query that instead.
Coming from a Rails world, the obvious solution would have been to use counter_cache and after_create callbacks and store the rolled-up counts for events in a separate table. There are a few problems with this however:
- Delegating this responsibility to the app layer is fraught with danger as we would have to do extra checks to make sure that we wrap these database writes/updates in transactions.
- Account for app deploys and restarts interrupting these callbacks and causing inconsistent values to be presented to the user.
- Callbacks in the app code are cause unintended effects (especially while running tests) that you have to account for.
- At the scale at which we were operating, we had to be careful for the callbacks to itself cause a thundering herd problem with updates to the same row in the rolled up table.
It was clear to us at this point that we needed a solution that was native to the database. Enter Citus.
Postgres Triggers, Upserts and Queues
Thanks to the amazing content from the folks at Citus, I came across a reference implementation of how rollups can be implemented in a sane way. You should definitely watch the video tutorial, but the TL;DR is:
- Use Postgres triggers (upon
INSERTof row in the events table) to queue up count data to an intermediate table (calledrolledup_events_queue). - At a specified frequency (with some jitter so as to avoid the thundering herd problem), we use Postgres 9.5’s
UPSERTfeature to take all of the pending counts in therolledup_events_queuetable and roll them up (by hour) in therolledup_eventstable.
The function that is invoked to flush the rolledup_events_queuetable is presented here:
- The Query Engine then queries from the
rolledup_eventstable. Due to the highly dense nature of conversational metrics (messages between agent and user happen in a matter of seconds and minutes), in initial testing we were able to achieve rollup gains of 7x and massive increases in query performance.
The updated data flow model is presented here:
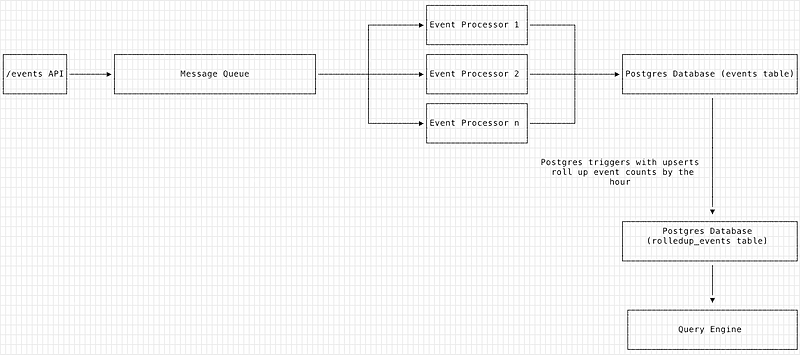
Deploying to Production
The next step was to deploy the system in production with zero-downtime and zero data-loss. Our de-coupled event processing system allowed us to perform upgrades to our database without any downtime.
(For the curious, we performed three dry runs of this process, ran scripts to make sure there was no data loss before we deployed the changes to production).
- During the upgrade process, we turned off the event processor engines which would take raw event data from the message queue and insert them into the database. (As a consequence of this, we warned users beforehand that their dashboards would not update in real-time for a few hours).
- Since our Postgres trigger was activated on
INSERTit would not take care of the millions ofeventrows that were in our database. So we created a second trigger function that also worked onUPDATEand updated theupdated_atcolumn for all of the events rows in batches. Once the migration was complete, we deleted the trigger (although updates to event data are non-existent in any case). - Our Query Engine was then deployed which read from the
rolledup_eventstable instead of theeventstable and voila, we were in business.
The Results Are In & They Are Fantastic
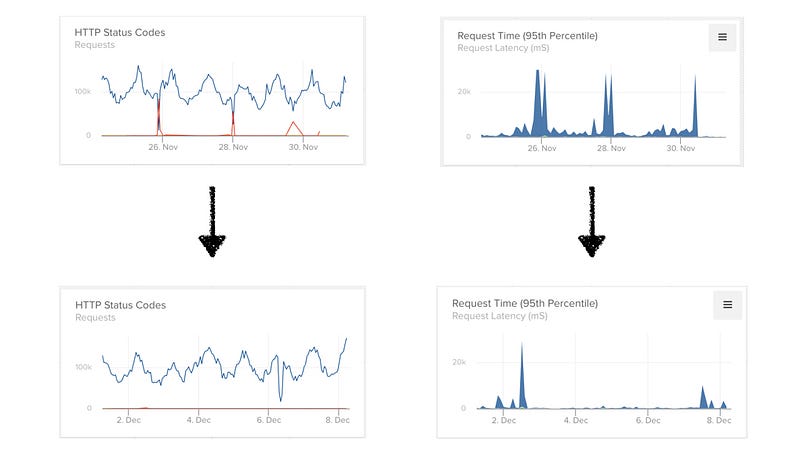

The deployment needed a couple of hours and we closely monitored the system for errors. With our testing we’d made sure that the performance results were many orders of magnitude better. Error rates (gateway timeouts) were eliminated, request time went down dramatically (upto 150x) and our deployment was a success.
This system has been powering Botmetrics for the last few months and we have since processed 250M+ events from all kinds of bots with median request latency of 100–300ms.
How Do We Scale From Here?
At some point the rolledup_events table is going to become large enough that queries to it will become slow as well. Where can we go from here?
- One strategy is to roll up at a higher granularity (day level) and so on for time ≥ n months/days, etc.
- We are also considering sharding across multiple databases (with a services such as Citus).
We have been extremely happy with Postgres as our primary data store. Postgres’ flexibility in allowing us to use NoSQL paradigms (with JSONB) along with great features such as UPSERTs, native code triggers and a healthy ecosystem around it has allowed us to accelerate and adapt to growing traffic.
Botmetrics is the best and fastest way to measure, analyze and engage with your messaging audience. Sign Up Today for free!